들어가기 앞서 해당 글은 '혼자 공부하는 컴퓨터구조 + 운영체제'를 참고로 작성되었습니다.
CISC와 RISC는 각각 ISA(Instruction Set Architecture)의 한 종류이다.
ISA(Instruction Set Architecture)
전공책이나 다른 정보글에서 '아키텍쳐에 따라 어쩌구 저쩌구'하는 그 아키텍쳐가 바로 이것이다. ISA는 cpu가 이해할 수 있는 명령어의 모음을 가리킨다.
같은 cpu라고 해서 같은 명령어를 이해할 수 있는 것이 아니다. 이를테면 컴퓨터에 cpu가 들어있듯이 스마트폰에도 cpu가 있다. 하지만 컴퓨터의 실행 프로그램을 아무런 설정없이 스마트폰에서 실행하면 스마트폰의 cpu는 해당 프로그램을 이해하지 못해 실행이 되지 않는다는 말이다.
이것이 바로 아키텍쳐의 차이로 인한 것이다. 그럼 해당 아키텍처의 대표인 CISC와 RISC에 대해 알아보자.
CISC(Complex Instruction Set Computer)
결론부터 말하자면 'x86 아키텍처' 가 대표적인 CISC인데, 이를 기반으로 만든 cpu가 바로 인텔과 Amd가 되시겠다.
CISC의 약자에서 볼 수 있듯이 말그대로 '복잡한 명령어 집합을 활용하는 컴퓨터'를 의미한다. CISC의 특징을 그대로 보여주는 약자인데, CISC는 하나의 명령어가 다양한 기능을 담당하기 때문에 내부 구조가 상당히 복잡하다.
하나의 명령어가 다양한 기능을 하는만큼 컴파일된 어셈블리어를 까보면 같은 명령어로 다양한 내용을 처리하는 것을 볼 수 있다. 때문에 명령어가 짧게 끝나고 이는 명령어를 적게 사용하기 때문에 메모리를 절약할 수 있다는 장점이 있다.
하지만 여기서 이상한 점이 있다. 장점으로 '메모리 공간을 절약할 수 있다.' 라고 하는데, 이는 실행 프로세스를 올리는 메모리 영역에 한에서는 맞는 말일지 몰라도, 한 명령어에 다양한 기능을 넣었다는 건 그만큼 명령어가 크다는 말이고 이는 다시 하나의 명령어가 차지하는 메모리 영역이 크다는 말이된다. 참으로 이상한 장점이 아닐 수 없다.
이는 CISC가 지향하는 바를 보면 의문이 풀리는데, CISC는 '명령어 하나'로 다양한 기능을 제공한다는 것이다. 이는 위에서 봤듯이 프로그램을 실행시키는데 필요한 명령어가 적다는 것이고, 큰 명령어가 저장된 것 보다 프로그램이 실행 될 때 동적으로 할당되는(또는 cpu가 읽을) 명령어가 적기 때문에 부담이 덜하다 라고 해석할 수 있겠다.
'하나의 명령어로 다양한 기능을 제공'은 명령어의 길이가 가변적이라는 특징으로 이어진다. 이 특징은 다시 치명적인 단점으로 이어지는데 가변적이라는 것은 상황에 따라 실행시간이 불규칙하다는 것이다. 이렇게 되면 명령어 파이프라인의 병렬 처리 또한 효율적이 못하게 된다는 단점이 된다.
이런 치명적인 단점이 있는 CISC을 왜 쓰는 걸까? 지금 말한 CISC의 특징들은 아주 옛날 CISC를 개념이 나온 초기의 특징이다. 현대에는 당연하게도 해당 단점을 보완하여 CISC지만 내부적으로 RISC와 비슷하게 동작하게 해 놓았다.
RISC(Reduced Instruction Set Computer)
약자에서 볼 수 있듯이 명령어 크기를 줄인 아키텍처다. CISC를 보완하기위해 명령어 크기를 줄인 대신 아래 이미지와 같이 컴파일된 명령어가 늘어났다.
RISC는 규격화된 고정 길이 명령어를 활용한다. 때문에 하나의 명령어가 웬만해선 1클럭 내외로 실행되기 때문에 명령어 파이프라이닝에 유리하게 되었다. 이는 실행 속도의 향상으로 이어진다.
또한 메모리에 직접 접근하는 명령어를 load, store 두 개로 제한했는데, 이는 메모리 접근을 단순화 하고 최소화하는 것을 추구하기 때문이다. 대신 레지스터를 적극적으로 활용하기 때문에 레지스터를 이용한 연산이 많아 일반적으로 범용 레지스터의 개수도 더 많다.
대표적인 아키텍처로 ARM 아키텍처가 있으며, 모바일 기기, 태블릿, 스마트폰 등에서 널리 사용된다.
책에서는 CISC에 대해 '많은 명령어 수로 적은 명령으로 프로그램을 실행 시킬 수 있다.' 라고 나와있다. 처음에 이게 무슨 말인가 싶어 고민을 많이 했더랬다. 언뜻 보면 맞는 말 같지만 가만히 생각해 보면 이상한 말이 아닐 수 없었다. RISC에선 '명령어 종류가 적기 때문에 컴파일된 명령어들이 많다.'를 보면 더 이상하다. 종류가 적은데 왜 컴파일 된 명령어가 많단 말인가.
결론적으로 명령어 종류와 개수에 포커스를 맞추는 것이 아니고, 명령어 하나에 다양한 기능을 하느냐 아니면 명령어 하나는 딱 그 역할만 하느냐에 초점을 맞춰야 하는 게 맞는 것 같다.
아마 책에서는 '명령어'와 컴파일 '명령'을 구분한 게 아닐까 한다. 이 부분을 놓쳐 고민을 많이 한 거 같다.
책과 같은 설명으로는 헷갈릴 수 있으니 위에서 말한 '명령어 하나'를 기준으로 삼는 게 좋은 것 같다.
들어가기 앞서 해당 글은 '혼자 공부하는 컴퓨터구조 + 운영체제'를 참고로 작성되었습니다.
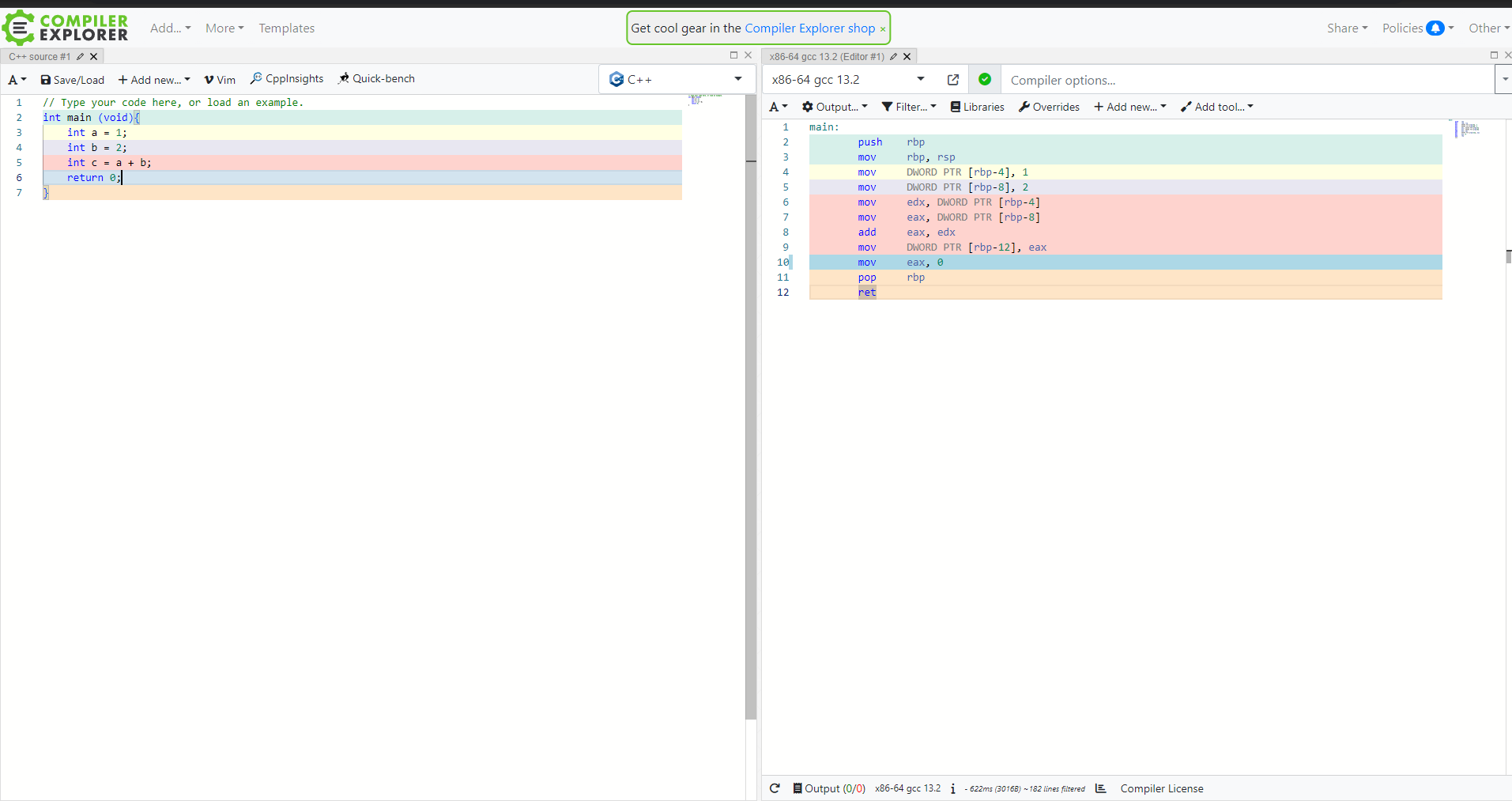
간단한 cpu 내부 구조
cpu는 제어 장치로 명령어를 해석하여 전기 신호로 동작하고, 필요한 데이터를 메모리로부터 불러와 레지스터에 임시로 저장하여 ALU는 레지스터의 값을 토대로 연산을 한다.
레지스터(Register)
레지스터는 ALU가 연산할 명령어와 데이터가 저장되는 장소다. 책에서 나온 기억해야할 레지스터는 다음과 같다.
들어가기 전에 cpu의 레지스터는 이름과 종류, 그리고 각 갯수 등에 대해선 제조사마다 여려가지다. 해당 사항을 유념하자.
프로그램 카운터
명령어 레지스터
메모리 주소 레지스터
메모리 버퍼 레지스터
플래그 레지스터
범용 레지스터
스택 포인터
베이스 레지스터
프로그램카운터(PC: Program Counter)
해당 레지스터에는 메모리에서 가져올 명령어의 주소를 저장한다.명령어 포인터(Instruction Pointer) 라고도 부른다.
명령어 레지스터(IR: Instruction Register)
말 그대로 해석할 명령어를 저장하는 레지스터다. 제어 장치는 해당 레지스터의 명령어를 해석하여 필요한 전기 신호를 보낸다.
메모리 주소 레지스터(MAR: Memory Adress Register)
메모리의 주소를 저장하는 레지스터다. 여기서 처음에 든 의문점이 "프로그램 카운터와 뭐가 다른가?" 였다. 이는 레지스터들의 이름만 봐도 알 수 있듯이 역할이 다르다. 후에 서술할 cpu의 동작방식을 보면 이해가 간다.
메모리 버퍼 레지스터(MBR: Memory Buffer Register)
메모리 데이터 레지스터(MDR: Memory Data Register) 라고도 불리며 데이터나 명령어가 저장되는 장소다. 이 또한 명령어 레지스터가 있는데 왜 굳이 또 해당 레지스터가 있는지 의문이 들지만 cpu의 동작 방식을 보면 이해된다.
해당 레지스터들은 다음과 같이 동작한다.
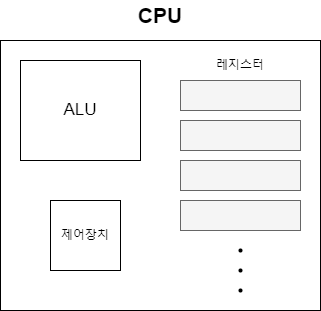
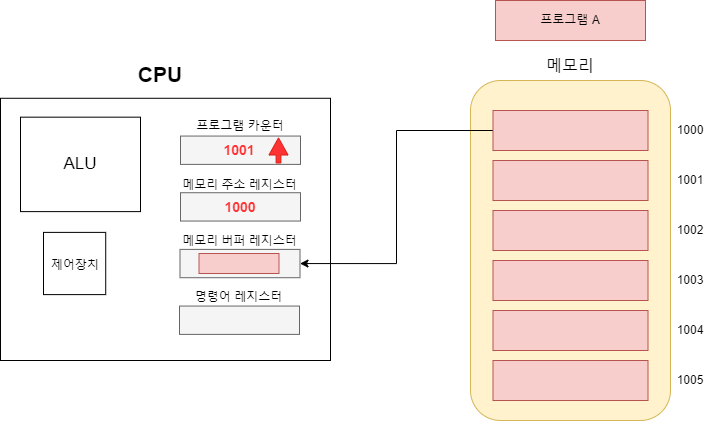
먼저 프로그램 카운터에 읽어 들일 메모리 주소가 저장된다. 프로그램 카운터에는 최초에는 시작 카운터, 후에는 다음에 읽어들일 메모리의 주소가 저장된다. 즉, 프로그램 카운터는 '읽어 들일 메모리의 가이드'를 하는 셈이다.
참고로 프로그램 카운터에 값을 넣는 역할은 운영체제가 담당한다.
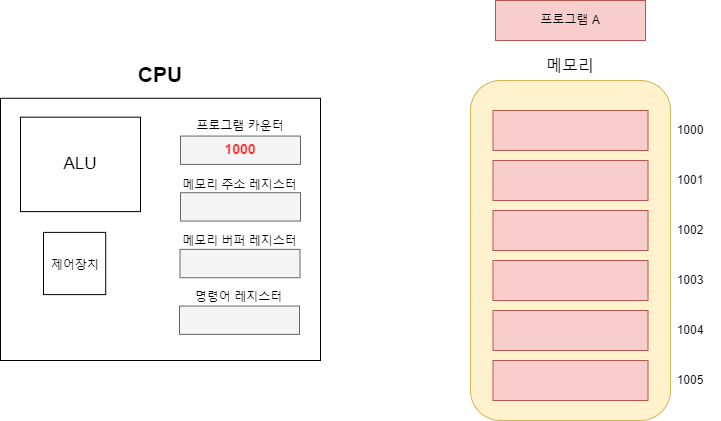
프로그램 카운터에 저장된 주소가 메모리 주소 레지스터에 저장된다. 즉, 메모리 레지스터에는 현재 읽어 들일 메모리를 가지고 있는 것이다. 메모리 주소가 저장되면 제어장치는 해당 주소를 읽으라는 제어 신호를 보낸다.
제어 신호를 받은 메모리는 해당 주소의 데이터(또는 명령어)를 보내게 되고 해당 데이터는 메모리 버퍼 레지스터에 저장된다. 이 때 프로그램 카운터가 오르면서 다음에 읽을 메모리를 가리키게 된다.
이로서 프로그램 카운터와 메모리 주소 레지스터의 차이점이 명확해 졌다. 현재 작업(1000)을 완료하면 프로그램 카운터에 저장된 다음 작업(1001)을 시작할 것이고 이런식으로 카운터가 증가하며 순차적으로 작업을 해 나갈 것이다.
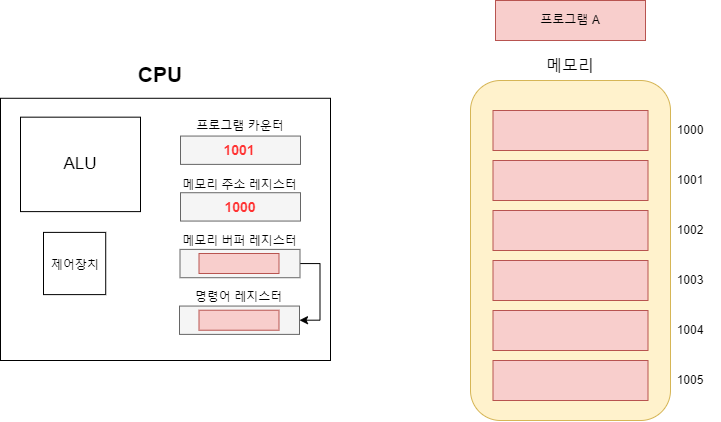
메모리 버퍼 레지스터에 저장된 값이 명령어이면 명령어 레지스터에 저장된다. 그림엔 없지만 만약 데이터 값이면 어큐뮬레이터(accumulator)라는 레지스터에 저장된다.
여기서 드는 의문점은 "메모리 버퍼 레지스터의 값을 왜 또 굳이 나눠서 저장을 하나?" 이다.
메모리에서 받는 값은 데이터가 될 수도 있고 명령어가 될 수도 있다. 그 말은 즉, 명령어와 데이터를 처리하는 과정이 다를 수 있으며 이 둘을 유동적으로 활용하기 위해서는 하나의 저장 장소가 아닌 각각의 저장 장소를 만드는 것이 더 효율적이다.
예를 들어 앞서 캐시 메모리에서 다루었듯이 캐시 메모리는 데이터를 예측하여 저장하는데, 명령어를 실행하는 동안 그 값을 미리 메모리 버퍼 레지스터에 저장하는 등으로 활용할 수 있을 것이다. 이는 버퍼에 대한 개념을 다시 상기하면 이해할 수 있는 내용이다.
명령어 레지스터에 명령어가 저장이 되면 제어장치는 저장된 명령어를 읽어 명령어를 처리한다. 1000번에 담긴 명령어가 가령 '80번 주소의 데이터를 가져와라' 라는 명령어라면 80번주소를 메모리 레지스터에 저장하고, 해당 주소를 토대로 메모리에 요청하여 그 값을 메모리 버퍼 레지스터에 저장한 후, 해당 데이터는 어큐뮬레이터에 저장되는 식이다.
이런식으로 1000번 주소의 작업이 끝나면 다음 주소인 1001번 주소의 작업을 시작하게 될 것이다. 만약 1001번 주소의 명령어가 '데이터를 더하라(ADD)라면 제어 장치는 ALU에 제어 신호를 보내 연산을 하고 결과값을 어큐뮬레이터에 저장한다.
cpu 동작에 대해서는 책의 내용만으로는 부족한 감이 있어해당 영상을 참고 하면 더욱 이해가 쉬울 것이다.
범용 레지스터(general purpose register)
이름 그대로 다양한 상황에 자유롭게 사용할 수 있는 레지스터다. 메모리 버퍼 레지스터는 데이터 버스로 주고받을 값만 저장하고, 메모리 주소 레지스터는 주소 버스로 내보낼 주소값만 저장하지만, 범용 레지스터는 데이터와 주소를 모두 저장할 수 있다.
플래그 레지스터(flag register)
cpu의 ALU의 연산 결과나 CPU의 상태에 대한 플래그 정보를 저장하는 레지스터다.
플래그 레지스터에는 다음과 같은 1비트 정보들이 있는데, 주로 ALU의 연산 결과에 의해 해당 비트들의 값이 정해진다.
플래그 종류
의미
부호 플래그
연산한 결과의 부호를 나타낸다.
제로 플래그
연산 결과가 0인지 여부를 나타낸다.
캐리 플래그
연산 결과 올립수나 빌림수가 발생했는지를 나타낸다.
오버 플로우 플래그
오버플로우가 발생했는지를 나타낸다.
인터럽트 플래그
인터럽트가 가능한지를 나타낸다.
슈퍼바이저 플래그
커널 모드로 실행 중인지, 사용자 모드로 실행중인지를 나타낸다.
스택 포인터(stack pointer)
메모리에는 스택 영역이 있다. 스택 포인터는 이 영역의 꼭대기. 다시말해 스택 영역에 마지막으로 저장된 메모리 주소를 가리킨다. 스택 포인터의 값을 관리함으로써 스택 메모리 영역을 벗어나는 오버플로나 언더플로를 방지한다.
베이스 레지스터(base register)
베이스 레지스터는 베이스 레지스터 주소 지정 방식에 쓰이는 레지스터다. 베이스 레지스터 주소 지정 방식은 변위 주소 지정 방식의 한 종류 인데, 변위 주소 지정 방식이란 명령어의 주소가 저장된 오퍼랜드 필드의 값에 특정값을 더하여 유효 주소를 얻어내는 방식이다.
즉, 베이스 레지스터 주소 지정 방식이란 오퍼랜드에 저장된 값에 베이스 레지스터의 값을 더하여 유효 주소를 얻는 방식이다. 예를 들어 베이스 레지스터에는 베이스가 되는 시작 주소가 저장 돼 있고, 오퍼랜드에는 100이라는 값이 저장 돼 있으면 베이스 주소로부터 100만큼 떨어진 주소를 얻을 수 있다.
비슷한 방법으로 상대 주소 지정 방식이 있다. 이는 프로그램 카운터 값을 더하여 유효 주소를 얻는 식이다.
그렇다면 그냥 주소를 불러오면 되지 언뜻 보면 번거로워 보이는 해당 방식을 도입했을까?
Array를 예로 들어 보겠다. Array는 주소의 배열인데, 만약 Array[3]에 접근할 때 변위 주소를 사용하면 해당 Array[3]는 명령어로 오퍼랜드 값에 3이 저장될 것이고 Array의 베이스 주소(시작 주소)로부터 3만큼 떨어진 주소를 찾아 줄 것이다. 만약 이와 같은 방법이 없다면 프로그래머는 Array[3]에 해당하는 정확한 주소를 명시적으로 알아야 할 것이며 이는 아주아주 불편할 수 밖에 없을 것이다.
해당 파트를 공부하면서 정말 많을 걸 느낀 것 같다. 처음 게임을 만들자고 공부를 시작했을 땐 학원에 절여져 굳이 컴퓨터에 대한 공부를 해야하나? 라고 했지만 지금은 전혀 아니다. 내가 어떤식으로 코딩을 해야 하는지에 대해 공부를 하면 할수록 감이 잡히는 느낌이다.
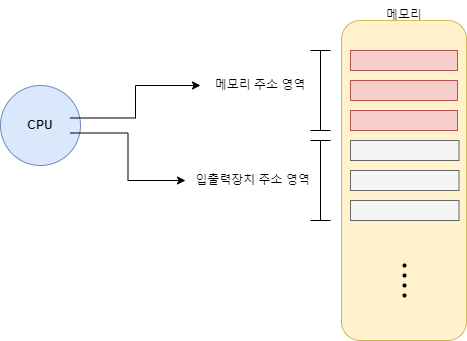
이 때 cpu는 명령을 내릴 장치 컨트롤러의 레지스터의 주소를 알아야하는데 해당 주소를 저장하는 방법이 크게 두 가지있다.
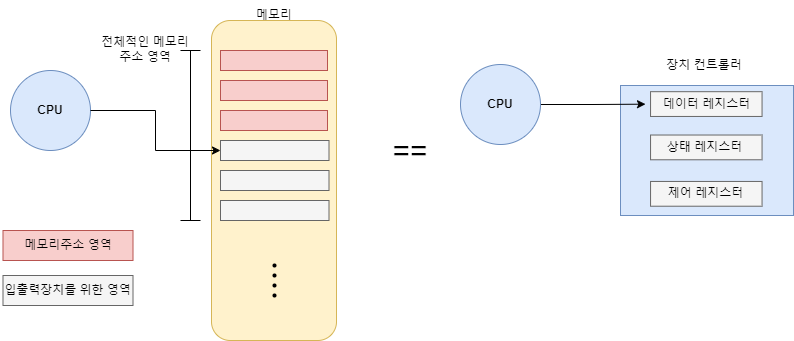
메모리 맵 입출력(memory mapped I/O)
메모리 맵 입출력은 한마디로 장치컨트롤러의 레지트터를 메모리(RAM)의 '메모리 주소 영역'의 일부처럼 쓰는 것이다.
장치컨트롤러의 레지스터를 메모리 주소 영역의 주소로 맵핑하여 해당 주소에 명령을 내리면 레지스터에 명령을 내리는 것과 동일하며, 이는 메모리 접근 명령어와 레지스터 접근 명령어가 다르지 않다는 장점이 있다.
예를 들어 '100'이라는 주소가 장치 컨트롤러의 데이터 레지스터를 가리키고 있다면 cpu는 장치 컨트롤러에 따로 접근할 필요없이 그냥 '주소 100에 데이터를 써라' 라는 명령만 내리면 된다.
다만, 메모리영역이 일반적인 메모리 영역과 입출력장치의 레지스터를 저장할 메모리 영역으로 나뉘게 돼 메모리 영역이 축소가 된다는 것이 단점이다. 또한 입출력 장치의 주소 공간이 메모리 주소 공간에 일부로 할당되기 때문에 충돌이 발생하지 않도록 주의해야 한다.
그렇다면 해당 메모리 주소가 장치 컨트롤러의 레지스터와 연결 돼 있다는 걸 어떻게 알고 cpu는 명령을 보낼까? 그 역할을 하는 것이 바로 운영체제다.
고립형 입출력(isolated I/O)
메모리 맵 입출력은 메모리 주소 영역을 분리하여 저장하고 마치 하나의 메모리 영역을 쓰는 것 처럼 데이터를 읽는 방식이라면 고립형 입출력은 반대로 다른 입출력 장치 만의 메모리 영역을 두어 전용 명령어로 접근하는 방식이다.
해당 방법은 메모리 맵과 달리 메모리 주소 공간이 축소되지 않는 특징을 가지고 있다.
인터럽트 기반 입출력(Interrupt-Driven I/O)
인터럽트 기반 입출력은 인트럽트글에서 다룬 비동기 인터럽트를 말한다. 장치 컨트롤러를 통해 cpu가 명령을 한 후 다른 작업을 하고 명령이 완료 되면 입출력장치는 장치 컨트롤러로 cpu에 인터럽트를 건다. 인터럽트를 받은 cpu는 현재 진행 중인 작업을 백업 한 후 인터럽트 서비스 루틴을 실행하고 작업이 완료되면 전에 진행했던 작업을 복구하여 계속 진행한다.
그럼 컴퓨터에는 입출력장치가 여러가지가 있는데 이 많은 장치들의 인터럽트를 cpu는 어떻게 처리할까?
기본적으로 인터럽트를 건 순서대로 처리하는 방법이 있겠다. 다만 순차적으로만 처리한다면 효율적으로 동작할 수 없다. 뒷순서에 왔지만 지금 당장 급한 인터럽트를 처리해야 할 경우도 있을 것이다.
때문에 각 인터럽트에는 우선순위가있으며, cpu는 우선순위가 높은 순서대로 인터럽트를 처리한다. 참고로 인터럽트 중 NMI(Non-Maskable Interrupt)는 우선순위가 가장 높아 인터럽트 비트를 비활성화 돼있어도 무시하고 제일먼저 처리 된다. NMI는 심각한 오류에 의한 인터럽트기 때문에 바로 처리 되어야한다.
인터럽트의 우선순위는 cpu가 하는 것이 아니라 PIC(Programmable Interrupt Controller) 라는 하드웨어에서 인터럽트의 우선순위를 정해 인트럽트 우선순위가 높은 것부터 cpu로 보내게 된다.
결국, 비동기 인터럽트 과정의 중간 단계에 PIC가 들어가며 처리 단계는 다음과 같다.
일반적으로 해당 그림처럼 PIC를 두 개 이상 계층적으로 구성한다.
1. cpu가 아닌 PIC가 인터럽트 요청 신호를 받는다.
2. PIC가 인터럽트의 우선순위를 판단한 후, cpu에 우선순위가 높은 순서 대로 인터럽트 요청을 한다.
3. cpu는 인터럽트 확인 신호를 보낸다.
4. PIC는 데이터 버스를 통해 cpu에 인터럽트 벡터를 보낸다.
5. cpu는 받은 인터럽트 벡터를 참조하여 해당 장치의 인터럽트 서비스 루틴을 실행하게 된다.
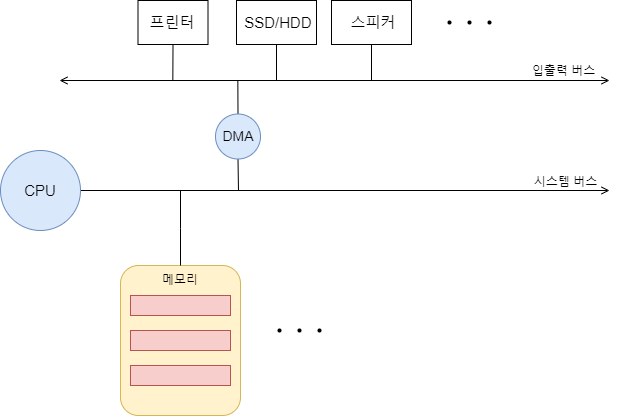
DMA(Direct Memory Access) 입출력
PIC와 같이 인터럽트의 우선순위를 정하는 하드웨어를 따로 둔 것 처럼 데이터의 입출력을 대신하는 장치가 있다. 그것이 DMA controller 라는 장치다. 인터럽트는 하던 작업을 중단하고 해당 인트럽트 서비스 루틴을 작업 하는 것인데, PIC가 우선순위를 정하여 하나씩 밀어준다 해도 많은 장치들의 인터럽트를 자주 받는다. 와중에 디스크 백업과 같은 대용량의 데이터를 옮긴다면 cpu의 부담은 높아 질 것이다.
DMA 컨트롤러는 데이터 전송에 대한 작업을 대신해준다. cpu가 DMA에게 입출력 작업을 명령하면 DMA는 마치 cpu처럼 입출력 장치와 상호 작용하며, 필요할 땐 이름과 같이 메모리에 직접 접근하여 작업하기도 한다. 그렇게 작업이 완료되면 cpu에게 완료했다는 인터럽트를 걸게 된다.
다만, cpu의 역할은 대신하는 만큼 DMA또한 데이터 전달 시 시스템 버스를 쓰게 된다. 시스템 버스는 공용 자원이기 때문에 cpu가 쓰면 DMA가 쓰지 못하고 DMA가 쓰면 cpu가 쓰지 못한다.
이를 해결하기 위해 DMA는 cpu가 시스템버스를 쓰지 않을 때 쓰거나 cpu에게 허락을 구하고 사용하지만, 현재 대부분 DMA와 입출력 장치들간에 입출력 버스 라는 연결 통로를 하나 더 두어 따로 쓴다.
참고로 앞서 말했듯 DMA는 데이터의 전송을 담당하는 장치이기 때문에 대량의 데이터 전송을 요구하는 저장 장치(SSD/HDD)나 프린터, 그래픽 카드, 사운드 카드(스피커) 등의 장치들에 쓰이며 키보드와 같은 간단한 인터럽트는 cpu에서 그대로 처리한다.