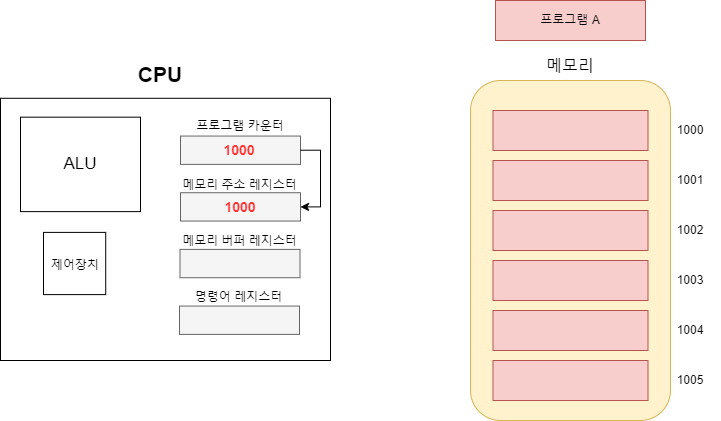
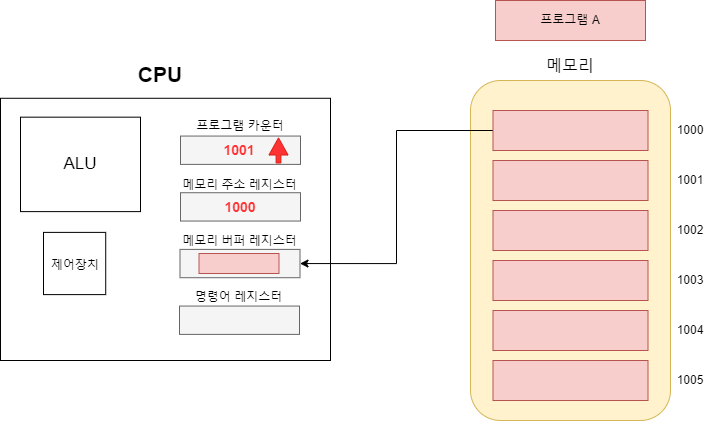
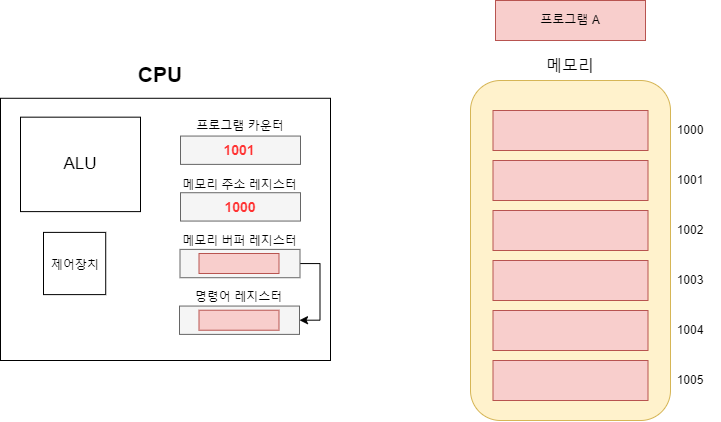
들어가기 앞서 해당 글은 '혼자 공부하는 컴퓨터구조 + 운영체제', ' 아브라함 실버샤츠 외 2명 저자인 운영체제(공룡책)' 를 참고로 작성되었습니다.
프로세스(process)
프로세스 디스크에 저장된 실행 파일에서 메모리에 적재되어 실행 중인 프로그램을 말한다.
프로세스는 메모리에 적재될 때 일반적으로 다음과 같이 배치된다.

- 텍스트 - 실행 코드
- 데이터 - 전역 변수(해당 영역은 초기화된 데이터와 초기화되지 않은 데이터 섹션으로 다시 나뉜다.)
- 힙 - 동적으로 할당되는 메모리
- 스택 - 임시 데이터 저장 장소(함수 매개변수, 복귀 주소 및 지역 변수)
스택과 힙의 방향은 두 공간 모두 동적으로 줄어들었다 늘어났다 하기 때문에 주소의 겹침문제를 예방하기 위해 스택은 높은 주소에서 낮은 주소로, 힙은 낮은 주소에서 높은 주소로 할당된다.
그럼 해당 프로세스를 운영체제는 어떻게 관리할까.
프로세스 제어 블록(PCB: Process Control Block)
cpu는 프로그램 카운터 레지스터에 실행할 명령어 주소를 저장한다고 했다. 그럼 그 주소는 누가 어떻게 알고 cpu에게 알려줄까 그 정보가 담긴 것이 바로 PCB다. PCB는 프로세스가 실행될 때 커널 영역에 생성된다. 운영체제는 해당 정보를 바탕으로 cpu와 상호작용하며 프로세스를 관리한다.
PCB에는 일반적으로 다음과 같은 정보를 포함한다.
- 프로세스 ID(PID: Process ID) : 프로세스를 식별하기 위한 프로세스 고유 번호다.
- CPU 레지스터 값 : cpu작업 중에 인터럽트가 걸리면 현재 작업 중인 내용을 백업한다고 했다. 그 정보들이 담기는 곳이다.
- 프로세스 상태 : 프로세스는 여러 상태를 가진다. 프로세스 생성 상태인 new, 실행 상태인 running, 대기 상태인 wating, 준비 상태인 ready, 종료 상태인 terminated를 가진다.
- CPU 스케줄링 정보 : 프로세스가 언제, 어떤 순서로 cpu를 할당받을지에 대한 정보다.
- 메모리 관리 정보 : 베이스 레지스터 주소 지정 방식을 위한 베이스 레지스터나, 한계 레지스터 값 등을 저장하는 장소다.
- 사용한 파일과 입출력 장치 목록 : 해당 프로세스가 어떤 파일을 열었는지, 어떤 입출력 장치가 해당 프로세스에 할당되었는지를 명시하는 장소다.
해당 정보들을 바탕으로 다음과 같이 관리된다.
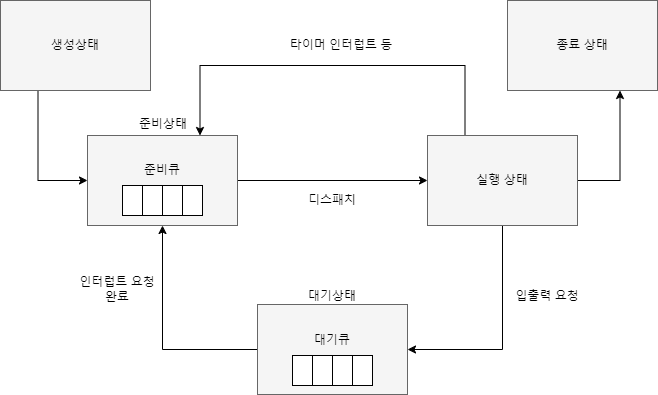
프로세스가 생성이 되면 생성 상태가 된다. 그리고 준비 상태로 준비 큐에 들어가 자기 차례를 기다린다. 프로세스가 실행이 되고 타이머 인터럽트 등 인터럽트가 발생하면 준비 큐에 들어가 대기한다. 입출력 인터럽트가 발생하면 대기 큐에 들어가 해당 인터럽트가 처리되길 기다린다. 처리가 완료되면 준비 큐에 들어가 실행을 대기한다.
준비 큐(ready queue)는 준비 큐는 일반적으로 연결 리스트로 저장된다. 큐 헤더에는 리스트의 첫 번째 PCB에 대한 포인터가 저장되고 각 PCB에는 준비 큐의 다음 PCB를 가리키는 포인터 필드가 포함된다.
대기 큐(wait queue)는 입출력 요청이 있을 시 해당 요청이 완료되기를 기다리는 큐다. 요청이 완료되면 다시 준비 상태로 들어가 실행을 기다린다.
사실 공룡책에서는 '프로세스 스케줄링' 이라고 cpu 스케줄링을 따로 분리하여 언급을 한 반면, 혼공운은 cpu스케줄링으로 통합하여 상태 다이어그램에 같이 다루었다. 혼공운 저자에게 문의하니 겹치는 내용도 많고 'CPU가 스케줄링한다', '프로세스가 스케줄링된다' 차이이기 때문에 같이 다루었다 한다.
다음은 문맥교환, cpu 스케줄링 순으로 계속 이야기 해 볼 생각이다.
'개발공부 > 운영체제 등' 카테고리의 다른 글
| 운영체제 개괄 (0) | 2023.12.10 |
|---|---|
| CISC와 RISC (1) | 2023.11.21 |
| 레지스터와 CPU 동작원리 (0) | 2023.11.21 |
| 여러 입출력 방법 (프로그램 , 인터럽트 , DMA) (0) | 2023.11.20 |
| 인터럽트(Interrupt) (0) | 2023.11.16 |