들어가기 앞서 해당 글은 '혼자 공부하는 컴퓨터구조 + 운영체제'를 참고로 작성되었습니다.
프로그램 입출력(Programmed I/O)
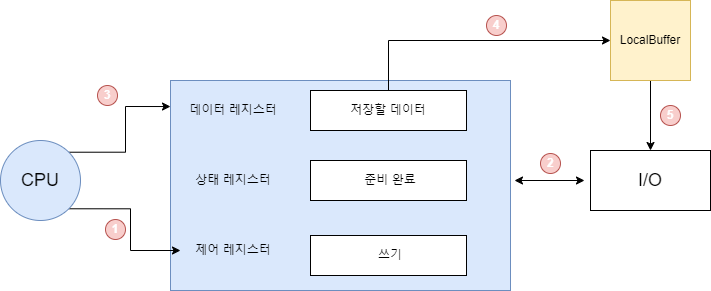
cpu가 입출력장치의 장치컨트롤러(device controller)와 상호작용하여 입출력 작업을 하는 것이다.
이에대한 이야기는 디바이스컨트롤러 글에서 다뤘다.
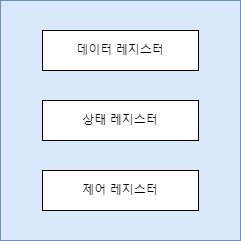
이 때 cpu는 명령을 내릴 장치 컨트롤러의 레지스터의 주소를 알아야하는데 해당 주소를 저장하는 방법이 크게 두 가지있다.
메모리 맵 입출력(memory mapped I/O)
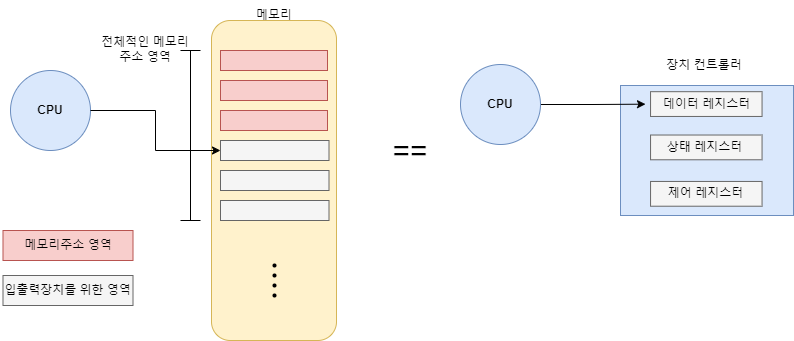
메모리 맵 입출력은 한마디로 장치컨트롤러의 레지트터를 메모리(RAM)의 '메모리 주소 영역'의 일부처럼 쓰는 것이다.
장치컨트롤러의 레지스터를 메모리 주소 영역의 주소로 맵핑하여 해당 주소에 명령을 내리면 레지스터에 명령을 내리는 것과 동일하며, 이는 메모리 접근 명령어와 레지스터 접근 명령어가 다르지 않다는 장점이 있다.
예를 들어 '100'이라는 주소가 장치 컨트롤러의 데이터 레지스터를 가리키고 있다면 cpu는 장치 컨트롤러에 따로 접근할 필요없이 그냥 '주소 100에 데이터를 써라' 라는 명령만 내리면 된다.
다만, 메모리영역이 일반적인 메모리 영역과 입출력장치의 레지스터를 저장할 메모리 영역으로 나뉘게 돼 메모리 영역이 축소가 된다는 것이 단점이다. 또한 입출력 장치의 주소 공간이 메모리 주소 공간에 일부로 할당되기 때문에 충돌이 발생하지 않도록 주의해야 한다.
그렇다면 해당 메모리 주소가 장치 컨트롤러의 레지스터와 연결 돼 있다는 걸 어떻게 알고 cpu는 명령을 보낼까? 그 역할을 하는 것이 바로 운영체제다.
고립형 입출력(isolated I/O)
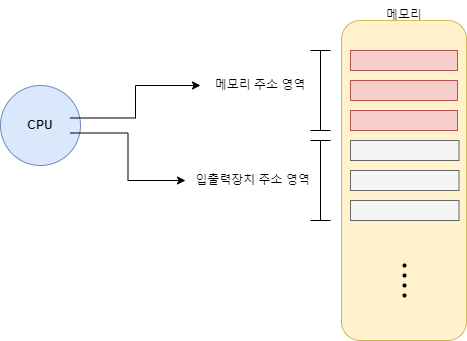
메모리 맵 입출력은 메모리 주소 영역을 분리하여 저장하고 마치 하나의 메모리 영역을 쓰는 것 처럼 데이터를 읽는 방식이라면 고립형 입출력은 반대로 다른 입출력 장치 만의 메모리 영역을 두어 전용 명령어로 접근하는 방식이다.
해당 방법은 메모리 맵과 달리 메모리 주소 공간이 축소되지 않는 특징을 가지고 있다.
인터럽트 기반 입출력(Interrupt-Driven I/O)
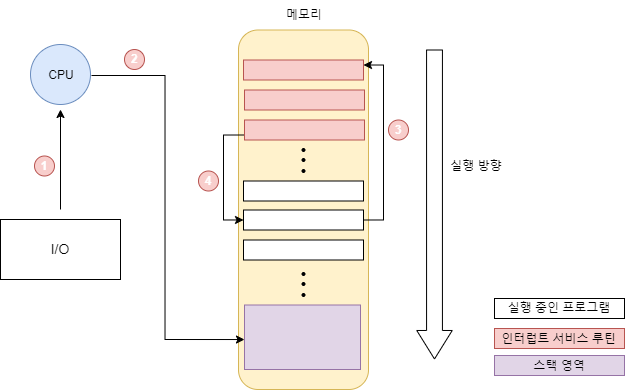
인터럽트 기반 입출력은 인트럽트 글에서 다룬 비동기 인터럽트를 말한다. 장치 컨트롤러를 통해 cpu가 명령을 한 후 다른 작업을 하고 명령이 완료 되면 입출력장치는 장치 컨트롤러로 cpu에 인터럽트를 건다. 인터럽트를 받은 cpu는 현재 진행 중인 작업을 백업 한 후 인터럽트 서비스 루틴을 실행하고 작업이 완료되면 전에 진행했던 작업을 복구하여 계속 진행한다.
그럼 컴퓨터에는 입출력장치가 여러가지가 있는데 이 많은 장치들의 인터럽트를 cpu는 어떻게 처리할까?
기본적으로 인터럽트를 건 순서대로 처리하는 방법이 있겠다. 다만 순차적으로만 처리한다면 효율적으로 동작할 수 없다. 뒷순서에 왔지만 지금 당장 급한 인터럽트를 처리해야 할 경우도 있을 것이다.
때문에 각 인터럽트에는 우선순위가있으며, cpu는 우선순위가 높은 순서대로 인터럽트를 처리한다. 참고로 인터럽트 중 NMI(Non-Maskable Interrupt)는 우선순위가 가장 높아 인터럽트 비트를 비활성화 돼있어도 무시하고 제일먼저 처리 된다. NMI는 심각한 오류에 의한 인터럽트기 때문에 바로 처리 되어야한다.
인터럽트의 우선순위는 cpu가 하는 것이 아니라 PIC(Programmable Interrupt Controller) 라는 하드웨어에서 인터럽트의 우선순위를 정해 인트럽트 우선순위가 높은 것부터 cpu로 보내게 된다.
결국, 비동기 인터럽트 과정의 중간 단계에 PIC가 들어가며 처리 단계는 다음과 같다.

1. cpu가 아닌 PIC가 인터럽트 요청 신호를 받는다.
2. PIC가 인터럽트의 우선순위를 판단한 후, cpu에 우선순위가 높은 순서 대로 인터럽트 요청을 한다.
3. cpu는 인터럽트 확인 신호를 보낸다.
4. PIC는 데이터 버스를 통해 cpu에 인터럽트 벡터를 보낸다.
5. cpu는 받은 인터럽트 벡터를 참조하여 해당 장치의 인터럽트 서비스 루틴을 실행하게 된다.
DMA(Direct Memory Access) 입출력
PIC와 같이 인터럽트의 우선순위를 정하는 하드웨어를 따로 둔 것 처럼 데이터의 입출력을 대신하는 장치가 있다. 그것이 DMA controller 라는 장치다. 인터럽트는 하던 작업을 중단하고 해당 인트럽트 서비스 루틴을 작업 하는 것인데, PIC가 우선순위를 정하여 하나씩 밀어준다 해도 많은 장치들의 인터럽트를 자주 받는다. 와중에 디스크 백업과 같은 대용량의 데이터를 옮긴다면 cpu의 부담은 높아 질 것이다.
DMA 컨트롤러는 데이터 전송에 대한 작업을 대신해준다. cpu가 DMA에게 입출력 작업을 명령하면 DMA는 마치 cpu처럼 입출력 장치와 상호 작용하며, 필요할 땐 이름과 같이 메모리에 직접 접근하여 작업하기도 한다. 그렇게 작업이 완료되면 cpu에게 완료했다는 인터럽트를 걸게 된다.
다만, cpu의 역할은 대신하는 만큼 DMA또한 데이터 전달 시 시스템 버스를 쓰게 된다. 시스템 버스는 공용 자원이기 때문에 cpu가 쓰면 DMA가 쓰지 못하고 DMA가 쓰면 cpu가 쓰지 못한다.
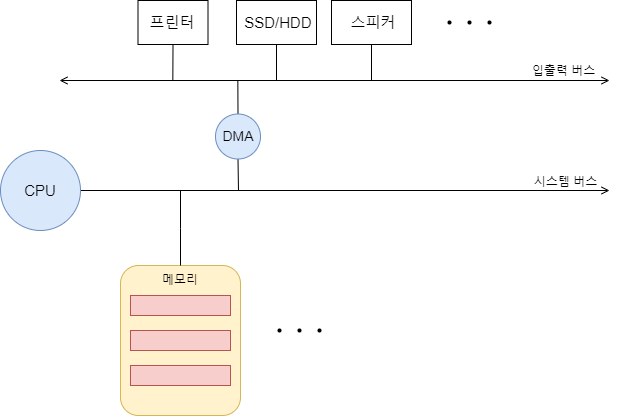
이를 해결하기 위해 DMA는 cpu가 시스템버스를 쓰지 않을 때 쓰거나 cpu에게 허락을 구하고 사용하지만, 현재 대부분 DMA와 입출력 장치들간에 입출력 버스 라는 연결 통로를 하나 더 두어 따로 쓴다.
참고로 앞서 말했듯 DMA는 데이터의 전송을 담당하는 장치이기 때문에 대량의 데이터 전송을 요구하는 저장 장치(SSD/HDD)나 프린터, 그래픽 카드, 사운드 카드(스피커) 등의 장치들에 쓰이며 키보드와 같은 간단한 인터럽트는 cpu에서 그대로 처리한다.
'개발공부 > 운영체제 등' 카테고리의 다른 글
| CISC와 RISC (1) | 2023.11.21 |
|---|---|
| 레지스터와 CPU 동작원리 (0) | 2023.11.21 |
| 인터럽트(Interrupt) (0) | 2023.11.16 |
| 디바이스 컨트롤러(Device Controller) (0) | 2023.11.16 |
| 버퍼와 캐시 (0) | 2023.11.15 |